TeraPad とは
TeraPad はフリーのテキストエディタです. HTML,C/C++ 言語などのキーワード強調表示機能があり,シフト JIS,JIS,EUC,Unicode などの文字コードに対応しているなど,テキストエディタに備わっていてほしい大抵の機能が実装されています. USB メモリに入れておけば,様々な場面で重宝します.
TeraPad のインストール
管理者 (Administrator) 権限を持つユーザでインストール作業を行うことを推奨します.
ここでは USB メモリを PC に挿入したときに認識されるドライブレターが (U:) であるものとして説明し,このドライブのことを USB ドライブと呼びます.
- 公式 Web ページ から最新の TeraPad をローカルディスクの適当なフォルダ (
C:\tempなど) にダウンロードします. ダウンロードするファイルは,拡張子が「.exe (インストーラ付き)」のものではなく,「.zip」の方を選びます. - ダウンロードした TeraPad の配布ファイル (zipファイル) を,USB ドライブの適切なフォルダ (以下,
U:\binとします) に展開 (解凍) します. Windows PC で展開 (解凍) を行うには,zip ファイルを右クリックして表示されるメニューから「すべて展開」を選び,展開 (解凍) 先フォルダを指定すればよいでしょう. - 展開先 (
U:\bin) の中にあるusr.txtをusr.iniというファイル名でコピーします. usr.iniを「メモ帳」などのテキストエディタで開き,すべてのユーザーが実行ファイル (TeraPad.exe) と同じフォルダにある設定ファイルを使用する設定 (UserIni=0) であることを確認します.- 展開先 (
U:\bin) の中にあるTeraPad.exeを起動してみます. 無事に起動できたら,表示-オプション を開き,図1の TeraPad のオプションダイアログボックスを表示させ,「表示」タブの「マーク」の中にある全項目 (TAB, 改行, EOF, 半角空白, 全角空白) にチェックを付け,OK をクリックしておくことを推奨します.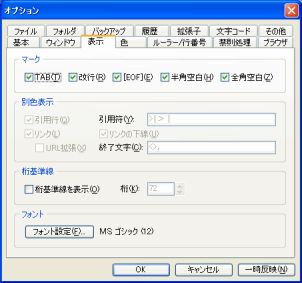
図1・TeraPad のオプションダイアログボックス - 展開先にある
TeraPad.exeを必要に応じてランチャ (PStart や PSMenu など) に登録します.
TeraPad による文字コード変換
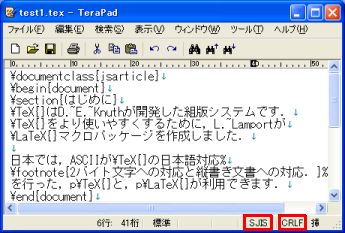
TeraPad の編集画面の下部にあるステータスバーの右側には,編集中のファイルに関する文字コードと改行コードが表示されています (図2 の赤枠). Windows で標準的に使用されるシフト JIS コードの場合は「SJIS」と表示されます. また,Windows で標準的に使用される改行コードは,ASCII コードで 0x0d に割り当てられた CR (Carriage Return; 復帰) と 0x0a に割り当てられた LF (Line Feed; 改行) の 2 バイトで「CRLF」と表示されます.
TeraPad で文字コードや改行コードを指定して保存するには,メニューバーから ファイル-文字/改行コード指定保存 をクリックします. 図3 のダイアログボックスが表示されるので,以下を参考に設定します.
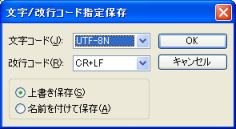
- 文字コード
- シフト JIS (Shift-JIS),JIS,EUC,UTF-16 (Unicode),BOM 無しの UTF-8 (UTF-8N),BOM 付きの UTF-8 (UTF-8) から選択します (詳しくは,【補足】文字コードについて を参照).
- 改行コード
- Windows 標準の CR+LF,Mac OS (9 まで) 標準の CR,UNIX 系で標準の LF から選択します.
- 保存方法
- 現在編集中のファイル名のまま上書き保存するか,別の名前を付けて保存するかを選択します. 前者を選んだ場合は OK ボタンのクリックにより上書き保存が行われ,編集画面に戻ります. 後者を選んだ場合は OK ボタンをクリックすると「名前を付けて保存」ダイアログボックスが表示されます.
編集画面に戻ったら,ステータスバーの文字コード,改行コードが指定した通りになっているか確認しましょう (図2 参照).
【補足】文字コードについて
文字コードの正式な名称は,IANA (Internet Assigned Number Authority) が管理する character-sets (英文) に登録されています. これによれば,シフト JIS の正式名は Shift_JIS,JIS コードの正式名は ISO-2022-JP,EUC コードの正式名は EUC-JP,UTF-16 (Unicode) の正式名は UTF-16 であるようです. また,UTF-8 の正式名は BOM の有無に関わらず UTF-8 であるようです.
BOM とは Byte Order Mark の略称で,Unicode で作成されるファイルの先頭に書き込まれるエンディアン (endian) 識別用の値のことで,UTF-16 では 16 進数で 0xfeff が用いられます. エンディアンには 2 バイト以上のデータ (例. 0xfeff) をメモリやファイルに格納するときに,先頭側から上位バイト (0xfe)→下位バイト (0xff) の順で格納されるビッグエンディアンと,その逆 (0xff→0xfe) となるリトルエンディアンの 2 種類があります. TeraPad で文字コードを Unicode に指定するとリトルエンディアンで保存されるようです.
UTF-8 は 8 ビット単位の文字コードですので,エンディアンの問題は発生しないのですが,0xef,0xbb,0xbf の 3 バイトをファイル先頭に BOM として加え,識別子として使用するソフトウェアもあるようです. 一方,BOM 無し (UTF-8N) でないと扱えないソフトウェアもあるようで,完全には統一されていないようです. もし UTF-8 対応をうたうソフトウェアが期待通りの動作をしない場合には,BOM の有無による動作の違いを確認してみるとよいでしょう.
なお「8 ビット単位の文字コード」は,1 文字を 8 ビットの文字コードで表現しているという意味ではありません. UTF-8 では ASCII コードに含まれるいわゆる半角文字は 1 バイト (8ビット) で表現されるのですが,ASCII コード外のいわゆる全角文字は 3 バイトで表現されます. このため,和文が多く使用されているシフト JIS のテキストファイルを UTF-8 に変換すると,ファイルサイズは 1.5 倍程度まで大きくなります (UTF-8 は最大 4 バイトで 1 文字を表現するため,もう少し大きくなる可能性もあります).